UAAP Real Time Sentiment Analysis of Fan Tweets
30 Aug 2019 | 4 minute read.It is UAAP season once again and this year’s season 82 is hosted by Ateneo it is a good time to take a look at one of my favorite projects I did during my senior year in college. This one is taken from the final project for CS 129.1: Special Topics in Software Engineering: Contemporary Database Technologies, more commonly known as “Contempo DB”. For this project, we did a real-time tweet analysis of tweets during the Final Four game of the Ateneo Blue Eagles and the FEU Tamaraws last November 25, 2018.
What we wanted to find out.
For the project, we wanted to find out through data analytics are three things.
- What percentage of the tweets regarding the UAAP game are toxic or not?
- Which fan base or contingent is more toxic?
- What are the most frequent words that fans use?
If you look at Twitter during these crucial collegiate games you see that most of the Philippine Trends are taken up by topics that are related to the game. However, due to the action happening in the games, some of the fans become overly passionate about their tweets. This means there is good data velocity coming from Twitter’s API and there a lot of emotionally charged tweets that we can analyze.
The technology we used.
The main technology that we used is mainly JavaScript based. NodeJS as a runtime and NPM Packages. For the data gathering we used the following:
- MongoDB with Mongojs as a driver
- Twit as a Twitter SDK wrapper for both the platform’s REST and Streaming APIs
- Sentiment (NPM Package)
- Dotenv to secure our API keys
For data visualization we did it via an express web app and used the following:
- Express
- EJS as a templating engine
- Chartkick.js
// Load environment variables
require('dotenv').config();
// Configure twitter API
const Twit = require('twit');
const config = require('./twitter_config');
const twitter = new Twit(config);
// Load sentiment analysis package
const Sentiment = require('sentiment');
const sentiment = new Sentiment();
const filipinoWords = require('./filipino');
// Configure mongoDB
const mongojs = require('mongojs');
const db = mongojs('tweets',['admu', 'feu'])
const filipino = {
extras: filipinoWords
};
const trackingWords = [
'ADMU',
'FEU',
// Plus many more
];
How did we do it?
We followed this simple methodology:
- Using Twitter’s streaming API, we subscribed to the ‘statuses/filter’ endpoint.
- Then we listened for tracking words related to the game and filter it to English (en) or Filipino (tl) words.
- Analyzed the tweet using a sentiment analysis package.
- Then we “classified” them to be either an Ateneo contingent or FEU contingent tweet.
For the sentiment analysis, we simply thought of toxic and good words in Filipino and translated it to English and set their score as the same as their English score. This is not the best way to do it but for our case, it was the best we can do at that time. We managed to come up with around 50+ toxic words and around 40+ good words.
console.log("Listening for tweets . . .");
const stream = twitter.stream('statuses/filter', {track: trackingWords, language: ['tl','en']})
stream.on('tweet',(tweet)=>{
if (tweet.retweeted_status === undefined){
let tweetText;
if (tweet.extended_tweet == undefined){
tweetText = tweet.text;
} else {
tweetText = tweet.extended_tweet.full_text
}
let analysis = sentiment.analyze(tweetText, filipino);
let tweetScore = tweet;
tweetScore.sentiment_analysis = analysis;
classifyTweet(tweetScore);
}
});
We first gather and analyze the tweets coming in from the Twitter API and save it to a MongoDB collection, with the sentiment score and the tokenized tweet, based on a simple classification logic: For negative sentiment score tweets, if it talks about a certain school or team it is classified on the opposing side. On the other hand for positive and neutral scored tweets we classify it to them as fans of the team they are talking about. This classification is happening as the tweets come by.
function classifyTweet(tweet){
let admuClassifiers =[
// Classifiers for AdMU here.
];
let feuClassifiers = [
// Classifiers for FEU here.
];
let tweetText;
if (tweet.extended_tweet == undefined){
regText = tweet.text;
tweetText = tweet.text.toUpperCase();
} else {
regText = tweet.extended_tweet.full_text;
tweetText = tweet.extended_tweet.full_text.toUpperCase();
}
for (let admu of admuClassifiers){
if (tweetText.includes(admu.toUpperCase())){
if (tweet.sentiment_analysis.score >= 0){
console.log(`Inserted to ADMU: Score ${tweet.sentiment_analysis.score} - ${regText}`);
return db.admu.insert(tweet);
} else {
console.log(`Inserted to FEU: Score ${tweet.sentiment_analysis.score} - ${regText}`);
return db.feu.insert(tweet);
}
}
}
for (let feu of feuClassifiers){
if (tweetText.includes(feu.toUpperCase())){
if (tweet.sentiment_analysis.score >= 0){
console.log(`Inserted to FEU: Score ${tweet.sentiment_analysis.score} - ${regText}`);
return db.feu.insert(tweet);
} else {
console.log(`Inserted to ADMU: Score ${tweet.sentiment_analysis.score} - ${regText}`);
return db.admu.insert(tweet);
}
}
}
}
After the gathering we did a map-reduce on the tokenized tweets that we got, for three different use cases, we didn’t include stop words for both English and Filipino that we got from our professor, for the map-reduce phase.
- Most used words/emojis
- Most used positive words/emojis.
- Most used negative words/emojis.
// Map functions
function getTokens1(){
var stopWords = [];
var tokens = this.sentiment_analysis.tokens
for(var token of tokens) {
if (token != "" && !stopWords.includes(token.toLowerCase())){
emit(token, 1)
}
}
}
function getTokens2(){
var stopWords = [];
var tokens = this.sentiment_analysis.positive
for(var token of tokens) {
if (token != "" && !stopWords.includes(token.toLowerCase())){
emit(token, 1)
}
}
}
function getTokens3(){
var stopWords = [];
var tokens = this.sentiment_analysis.negative
for(var token of tokens) {
if (token != "" && !stopWords.includes(token.toLowerCase())){
emit(token, 1)
}
}
}
// Reduce Function
function aggregateCount(key, values){
var count = 0;
for(var value of values){
count += value;
}
return count;
}
// Map Reduce Command Run in the MongoDB Shell
results = db.runCommand({
mapReduce: 'admu',
map: getTokens,
reduce: aggregateCount,
out: 'admu.wordcount'
});
results = db.runCommand({
mapReduce: 'feu',
map: getTokens,
reduce: aggregateCount,
out: 'feu.wordcount'
});
results = db.runCommand({
mapReduce: 'admu',
map: getTokens,
reduce: aggregateCount,
out: 'admu.positive'
});
results = db.runCommand({
mapReduce: 'feu',
map: getTokens,
reduce: aggregateCount,
out: 'feu.positive'
});
results = db.runCommand({
mapReduce: 'admu',
map: getTokens,
reduce: aggregateCount,
out: 'admu.negative'
});
results = db.runCommand({
mapReduce: 'feu',
map: getTokens,
reduce: aggregateCount,
out: 'feu.negative'
});
Results
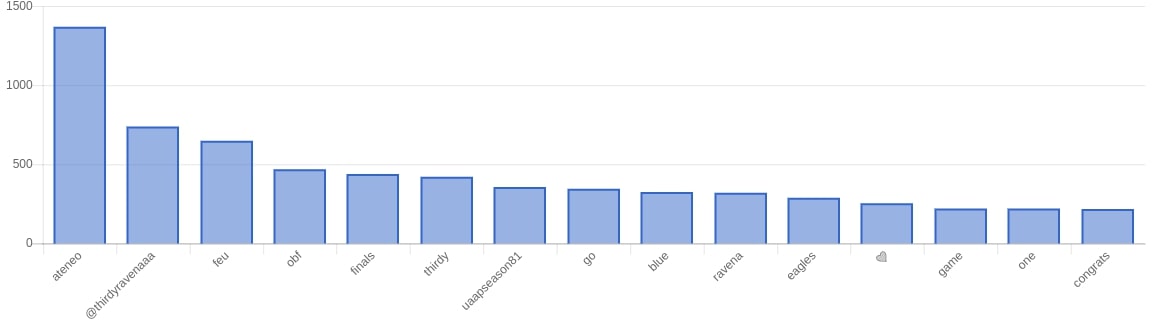
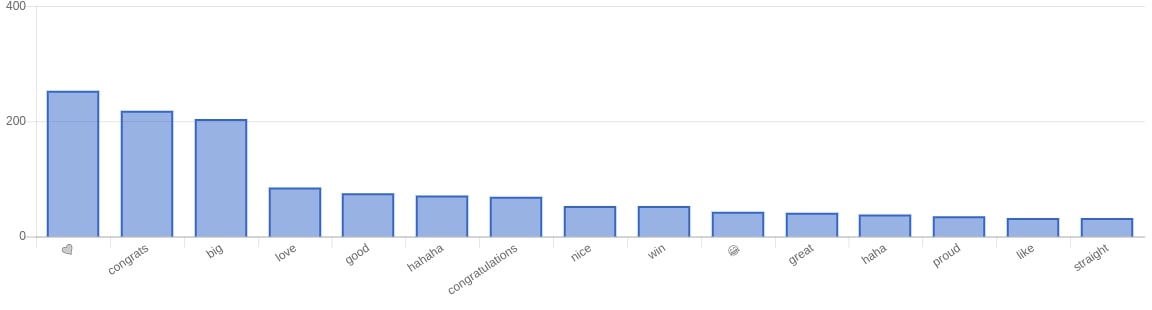
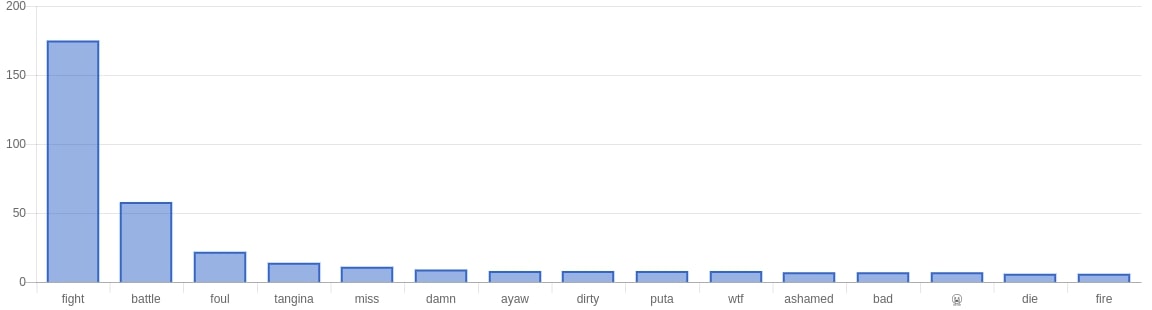
For our results in the web app we mainly looked at the following: using a bar graph we looked at the most frequently used words, most used positive words, most used negative words. Aside from that we also did Top 10 most positive tweets for both sides and a top 10 most negative tweets for both sides. Using chartkick.js we used an API endpoint to get the data for performance (gotta have that fast page load).
General Results
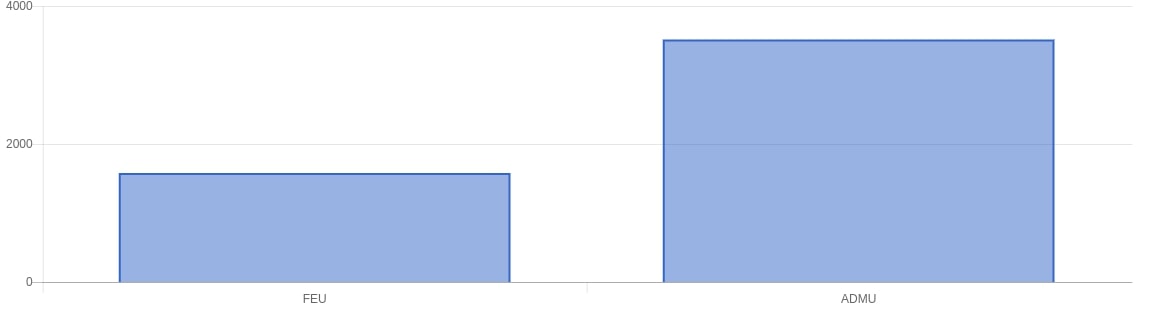
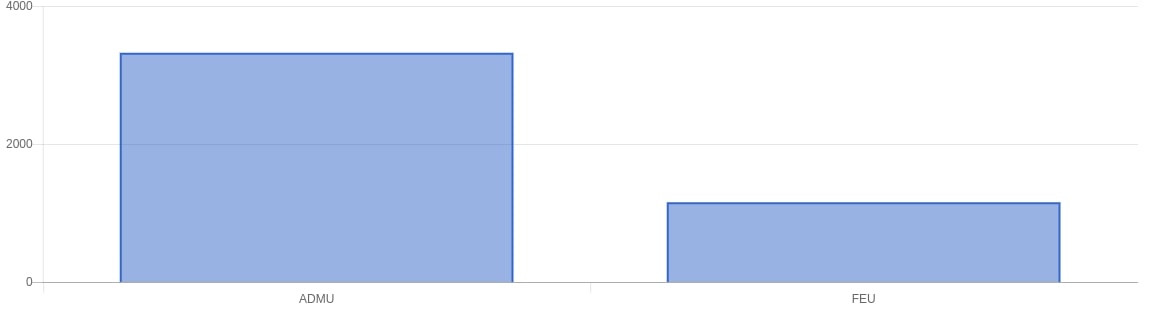
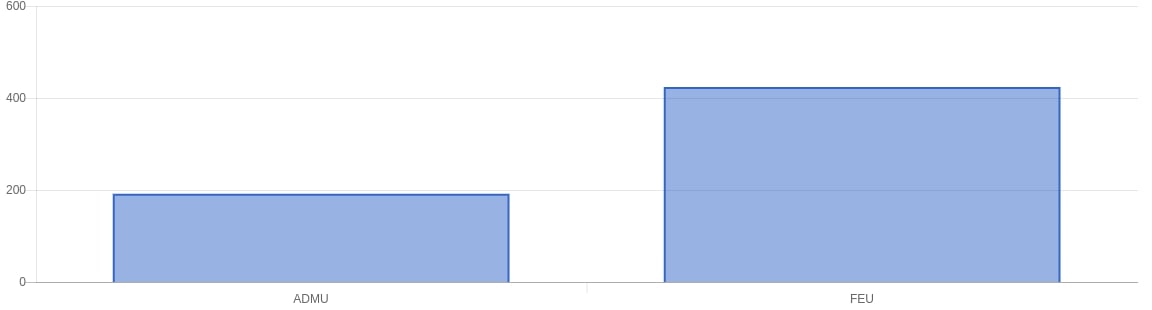
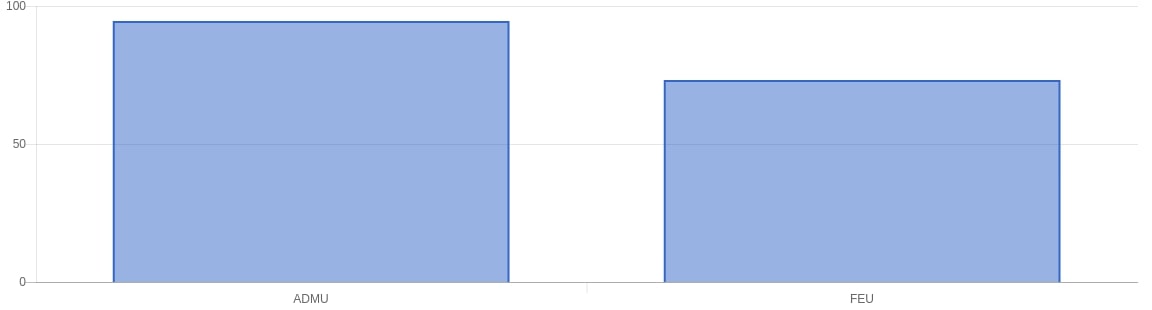
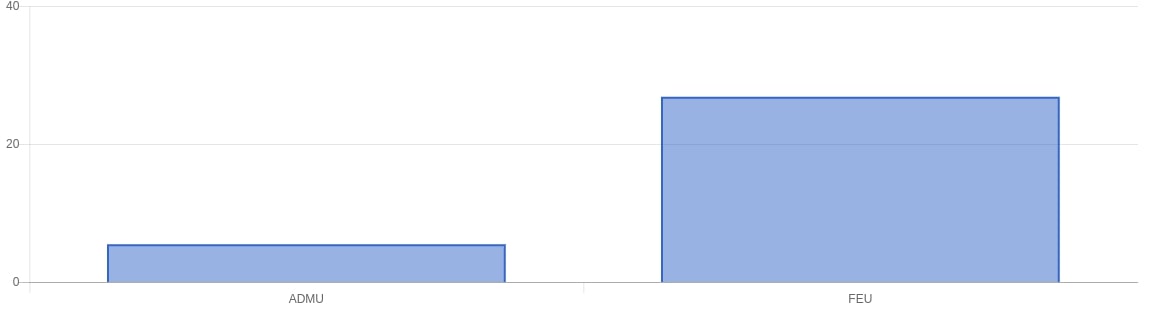
Looking at the Ateneo Tweets
Some examples of top positive tweets from Ateneo fans
| Tweet | Sentiment Score |
|---|---|
| LOVE YOUR ENERGY, @ThirdyRavenaaa 💙 WOOHOO! Galing, galing! | 14 |
| Thirdy’s maturity every year since high school has been amazing! What’s more amazing is the maturity of not his hops but of the maturity of his biceps triceps and shoulders!!! 💪🏻 Am I right? Haha! Good job @ThirdyRavenaaa !!! | 14 |
| Finals here we come!! 💙 Congratulations, Ateneo Blue Eagles 😃 Good luck sa finals 😊💙 #BEBOB #UAAPFinalFour #OBF | 13 |
Now some top negative tweets from Ateneo fans
| Tweet | Sentiment Score |
|---|---|
| Sino yung #21 sa FEU? Halatang halata ang pagbunggo kay Isaac aba!! Gago ka?? Kitang kita sa replay pwede ka dumaan sa iba talagang ganun pa ha? Bullshit ka. | -9 |
| Get yo shit in da basketball court Stockton. There’s no way that’s a basketball play. UAAP should ban that fool. #OBF | -9 |
| @alecstockton2 how are you doing now in the dugout Mr. Ill tempered piece of shit | -6 |
Looking at the FEU Tweets
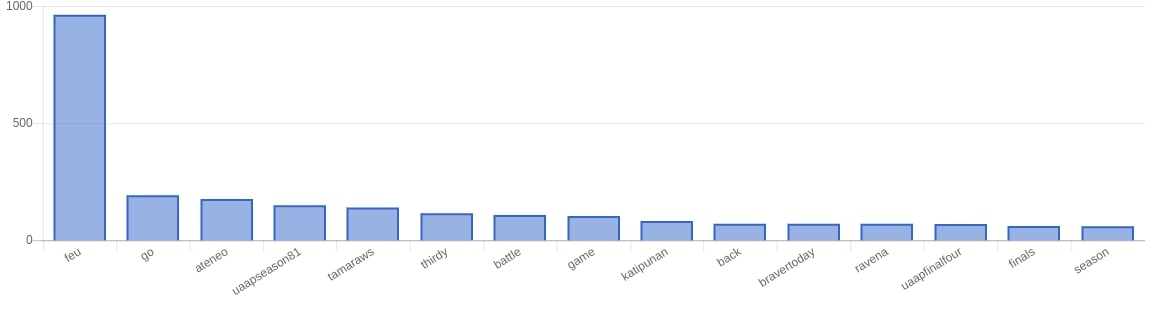
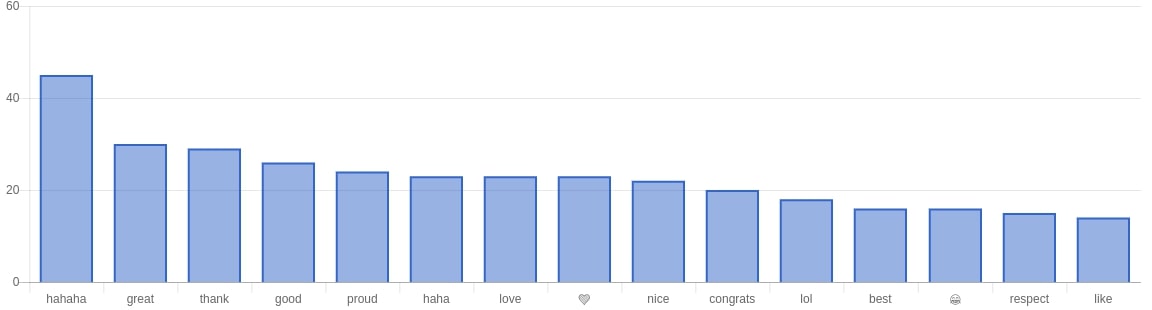
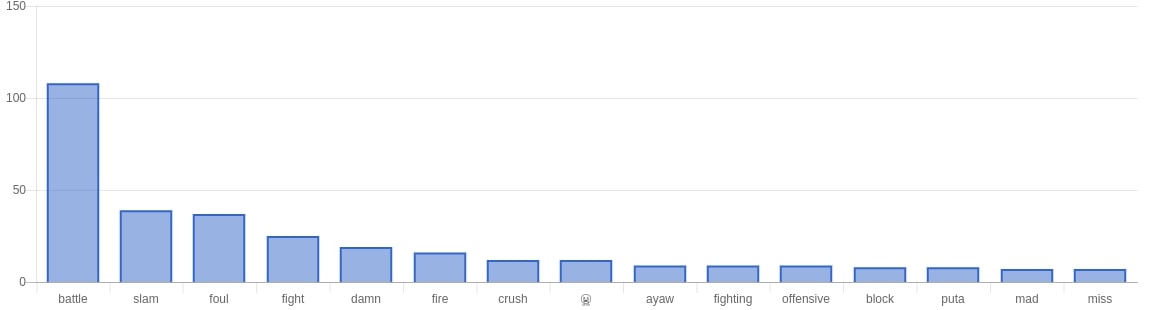
Some examples of top positive tweets from FEU fans
| Tweet | Sentiment Score |
|---|---|
| I will always be proud of you guys!! You have fought well! Let’s bounce back next year!! Braver!! 💪 Salute to all our graduating players 👏 You all have made the FEU Community so proud!! Thank you our brave Tams! Mahal namin kayo!! 💚💛 | 17 |
| Though far from home, our feet may roam Our love will still be true Our voices shall unite to praise thy name anew We’ll treasure within our hearts the FEU! Horns up, Tamaraws! 💚💛🔰 Atleast we made it to the final 4. Not bad at all, Congrats Areneyow! 🤣 | 15 |
| Nothing but love and respect to the FEU Men's Basketball team 💚💛 you guys did great! We'll bounce back strong next season. | 10 |
Now some top negative tweets from FEU fans
We even got a Bisaya tweet in the mix.
| Tweet | Sentiment Score |
|---|---|
| PUTANGINA MO KA WALA KANG MANNERS GAGO!!!! MGA FANS NG ATENEO BOO KAYO MGA QAQO | -9 |
| thirdy ravena ayaw paawat sus | -7 |
| Dili jud ni mawala ang BIASING pag magdula ang ATENEO ayy. Yawa mani si Thirdy Ravena. Playing victim pisteeee 🤬🤬🤬 di kayko ga watch ug basketball pero puta siya ✌🏼 | -7 |
Zipf’s Law
The results and the curve that it shows reminds me of a VSauce video that I watched before. See the video here:
In a nutshell, Zipf’s law just states that given a large sample of words used, the frequency of any word is inversely proportional to its rank in the frequency table. In mathematical terms, a word number n has a frequency proportional to 1/n.
Final Words
Me and my group are not data scientists, the methodology that we used is not perfect. We made this project specifically for a database class not necessarily a pattern recognition or data modeling class. The classification logic can be significantly improved and there are more things to analyze in tweets rather than sentiments. I encourage the use of Twitter’s excellent API to look into more possible data science use cases. I also included our presentation deck that has most of the points raised here and a video of our gatherer and classifier in action during the game itself.